This weekly report is actually a two monthly report! I just haven't had much enthusiasm for blogging. However, apart from last week (I was up in Nottingham visiting relatives) I have been busy on the Chess Tool case study previously mentioned. Lets start with the domain chart:

I'm only showing the Shaler-Mellor diagrams here. However, I will write up the case study as a multi-notation technical note in the future given Executable UML versions of all diagrams. The application domain covers Chess rules and the playing of Chess games. I spend a couple of weeks immersing myself in the world of Chess. The current OIM for the Chess domain is given below:

I've also modelled the lifecycles of matches, human players and computer players but I don't want to overload this blog with too many diagrams. They will all be in the final case study report. I will also leave further discussion of the Chess model to the report since I want to overview my other progress. I haven't progressed the User Interface domain far yet since I'm fairly confident I can tackle it last.
I initially placed the XML based Persistence domain above the Software Architecture domain as a proper service domain. This is fine for formatting purposes. However, for XML parsing the domain starts to rely heavily on metamodel mappings. Since this would make the case study more complicated than necessary I decided to move persistence below the software architecture, i.e. it's now an implementation domain allowing the XML parser factory logic to be hand coded. The J2SE XML parser will now load initial XML files parsing them into DOM structures which will now be traversed with custom code resulting in the population of initial Chess and User Interface object instances. This kind of decision as to what domains will be code generated and which won't needs to be made with care. Ones that should be excluded will often involve integration with existing libraries. In this case, I'm taking advantage of the J2SE XML libraries to do the actual parsing. If I was going to implement the low level parser then I would have kept persistence as a service domain.
After I looked at the Persistence domain, I moved onto the Software Architecture domain. I'm been on this for many weeks now. My intention with this case study was to manually generate code (since OOA Tool doesn't support Archetypes yet). However, I still want to model the architecture and design archetypes to control the manual generation of this code. I've gotten carried away with this! I starting with Data Values (and literal syntax) and the predefined operations supported by these values, moved onto Data Types (and declaration syntax) and the validation processes involved, then onto system, domain, object, attribute, link and operation instances. I then started to instantiate Chess versions of object instances etc. so I can understand what needs to be generated by archetype templates in future. In parallel, I created simulated versions of object instances etc. that could be used to run a simulation within OOA Tool in future. Since then I have been experimenting with mixed generated/simulated code. Complicated operation instances can be hand coded while simple operation instances can use Action Language parsed expressions. The current OIMs for Values, Types and Instances are shown below:

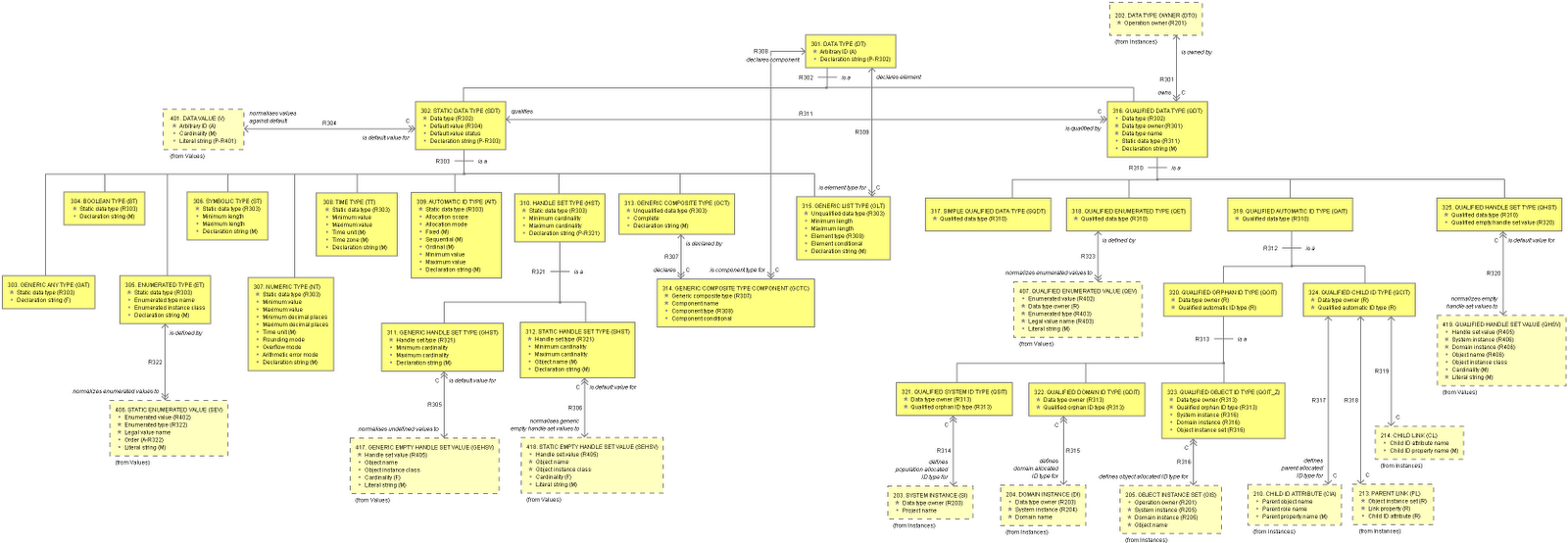

All of the above has been implemented in Java using Eclipse which I've been using for the first time trying to put JBuilder to bed. I'm starting to wonder If I can implement a complete Action Language driven virtual machine here which I hadn't planned to do for this case study. I will have to see how things go.
My experience with Eclipse has been mixed. Refactoring is much more powerful than in JBuilder 2005, but search and replace across a project is pretty crap in Eclipse. Maybe there is a plugin somewhere that fixes this. I'm also finding the debugger difficult to use. Maybe it just takes time and I've gotten used to the JBuilder debugger. One thing that annoys me is that the cursor in Eclipse seems to jump about a bit opening windows unexpectedly. I think there are some bugs here. I will say using generics in Eclipse is a completely different experience than trying to use it in JBuilder which is badly broken in that area.
I've also been using the released version of OOA Tool Build 014 to create the Chess Tool models. I have discovered a number of bugs during this process that required me to hack the XML to fix a corrupted "ChessTool.ooa" file. If anyone has a similar experience then they should email me their model I will fix them for you. I don't want to return to OOA Tool development at this time but I will document the bugs I have found (and associated workarounds) in the future.
I've also been following the debate on referential attributes in the Executable UML forum but my yahoo account doesn't seem to be working properly - it doesn't recognise my email when I try to login, yet it's still forwarding me email updates - weird! Referential attributes are crucial to the Shlaer-Mellor and Executable UML experience in my opinion. However, I have found situations were cardinality limits beyond zero-one-infinity can be beneficial in a model without creating models susceptible to change, e.g. a binary relationship in the Shlaer-Mellor metamodel has exactly two participants by definition. I may allow such explicit cardinality constraints to be shown on Shlaer-Mellor OIMs in the future.
No comments:
Post a Comment